Zero‑Reload Model Switching with vLLM Sleep Mode
Serve multiple LLMs on a single GPU without increasing VRAM, and finish faster, by combining vLLM Sleep Mode with a 1‑token warm‑up.
TL;DR
- Problem: Stage‑based pipelines often need to swap between different models. Reloading models each round burns time and VRAM.
- Solution: vLLM Sleep Mode offloads weights (and optionally frees them) so you can wake a model in ~0.1–0.4 s, run a 1‑token warm‑up, and then hit steady‑state latency on the first user request.
- Result: Across six alternating prompts (two models, three rounds), Sleep Mode + warm‑up is ~2.7× faster than reloading models each time, 69.2 s vs 188.9 s, with prefix caching disabled.
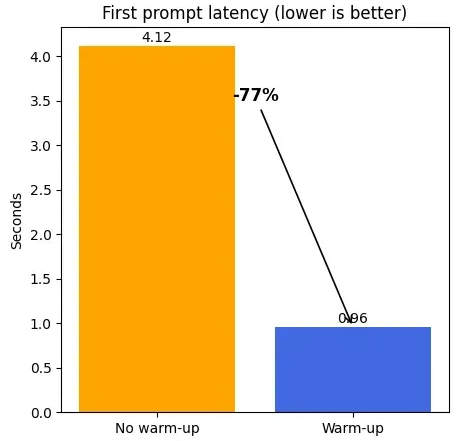
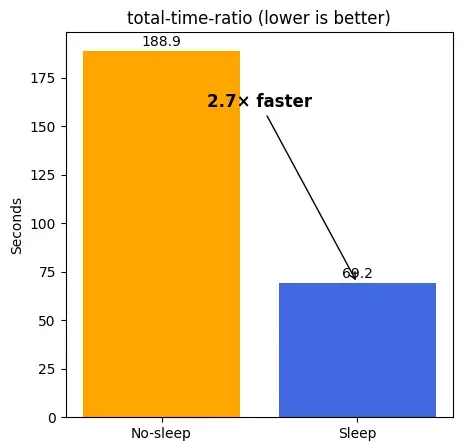
Figures 1 & 2 — End-to-end time & first-prompt latency (lower is better). Two models, 6 alternating prompts; Sleep L1 + 1-token warm-up. Total time: 69.2 s vs 188.9 s (~2.7× faster). First-prompt (after wake): 4.12 s → 0.96 s (–77%).
Why Sleep Mode
The problem. In multi‑stage pipelines (e.g., classify → caption → rerank), different steps call different models. On a single GPU, naïve orchestration reloads models from disk each time, repeatedly incurring initialization, allocator priming, and other cold‑start costs. VRAM also prevents keeping multiple models resident.
Sleep Mode (CUDA‑only). vLLM’s Sleep Mode keeps the server up while reducing GPU footprint:
- Level 1 — Offload model weights to CPU RAM and discard KV cache.
- Use when you plan to switch back to the same model.
- Wake is fast because weights are already in host memory.
- API:
POST /sleep?sleep_level=1thenPOST /wake_up
- Level 2 — Discard both weights and KV cache (free on CPU + GPU).
- Use when switching to a different model or updating weights; the next wake will reload from disk.
- API:
POST /sleep?sleep_level=2thenPOST /wake_up
Works on multi‑GPU too. If you serve large models with tensor parallelism (TP) or pipeline parallelism (PP), Sleep Mode offloads/frees each partition across devices in the same way. The control endpoints are identical; the speed‑up dynamics remain (wake is cheap, reload is expensive), only the absolute times change.
Setup
Hardware
- CPU: Ryzen 7 7900x
- GPU: RTX A4000 (PCIe 4.0 x16)
- RAM: 64 GB DDR5
Software
- vLLM 0.10.0 (older versions may work similarly)
- CUDA (required; Sleep Mode is CUDA‑only)
Models
Qwen/Qwen3-0.6B(text, compact reasoning)HuggingFaceTB/SmolVLM2-2.2B-Instruct(lightweight VLM)
Common flags
-enable-sleep-mode-no-enable-prefix-caching(prefix caching disabled for fairness)-compilation-config '{"full_cuda_graph": true}'(baseline runs)-dtype auto(bf16 if supported; otherwise fp16)-trust-remote-code(needed by many VLMs, including SmolVLM2)
Quantization: none for these runs. If you quantize, the absolute latencies change but the patterns (cold‑start vs steady‑state) remain.
Method
Scenario. Two models, three alternating rounds (A→B→A→B→A→B). One prompt per model per round.
Policy.
- Sleep Mode runs:
- Load both models once (steady state), then for each turn:
- wake → warm‑up (1 token) → prompt → sleep (L1)
- We use Sleep Level 1 because we switch back to the same models later.
- Load both models once (steady state), then for each turn:
- No‑sleep baseline:
- Reload the needed model from disk each time.
- No explicit warm‑up call: the cold‑start cost is embedded into the first prompt latency on every round.
Controls.
- Prefix caching disabled (
-no-enable-prefix-caching). - Same prompts across runs.
- Measured total wall time; TTFT observed but not used to drive control flow.
- CUDA Graph enabled in baseline; other ablations (eager mode, CG off) did not remove the cold‑start spike.
- Concurrency: single request at a time, to isolate first‑prompt effects.
Results
Canonical end‑to‑end comparison
Condition: Sleep Mode (L1), warm‑up ON, CUDA Graph ON, eager OFF, prefix caching OFF.
Workload: Two models, three rounds, one prompt per turn, single‑threaded.
- Sleep + warm‑up: 69.2 s total
- No‑sleep: 188.9 s total
- Speed‑up: ~2.7×
Warm‑up removes the first‑prompt spike
Condition: Second model’s first inference after wake; Sleep Mode (L1); prefix caching OFF.
A single 1‑token warm‑up right after wake_up reduces the first‑prompt latency from 4.12 s → 0.96 s (77%). Subsequent prompts stay at steady state; you pay the warm‑up once per wake.
Why the big gap vs no‑sleep? In no‑sleep, you reload from disk every round, and the cold‑start cost is repaid repeatedly because there’s no persistent server state. In Sleep Mode, you pay a small wake + warm‑up and keep the process hot.
What causes the first‑prompt spike?
It’s not (just) token length; it’s general cold‑start work concentrated in the first request:
- CUDA runtime/driver initialization paths
- TorchInductor graph specialization and/or JIT compilation
- CUDA Graph capture (if enabled)
- Memory allocator priming and graphable pool setup
- Prefill‑path specialization (e.g., attention mask/layout)
Flipping CUDA Graph off or enforce‑eager on didn’t eliminate the spike in our tests; both still need allocator setup and prefill specialization. A 1‑token warm‑up absorbs these costs so user‑visible requests start in steady state.
Quickstart
The fastest way to use Sleep Mode today—just what you need, nothing else.
# 1) Install
pip install vllm==0.10.0
# 2) Start a server (CUDA only)
export HF_TOKEN=...
export VLLM_SERVER_DEV_MODE=1 # dev endpoints; run behind your proxy
vllm serve Qwen/Qwen3-0.6B \
--enable-sleep-mode \
--no-enable-prefix-caching \
--port 8000
Sleep / Wake
# Sleep Level 1 (weights → CPU, KV cache cleared)
curl -X POST localhost:8000/sleep?sleep_level=1
# Wake
curl -X POST localhost:8000/wake_up
Warm‑up (1 token) + prompt
# Warm-up: absorbs cold-start; keeps first user request fast
curl localhost:8000/v1/chat/completions -H 'content-type: application/json' -d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [{"role":"user","content":"warm-up"}],
"max_tokens": 1, "temperature": 0, "top_p": 1, "seed": 0
}'
# Real prompt
curl localhost:8000/v1/chat/completions -H 'content-type: application/json' -d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [{"role":"user","content":"Give me a fun fact about the Moon."}],
"max_tokens": 32, "temperature": 0, "top_p": 1, "seed": 0
}'
Multi‑GPU note: Works with TP/PP as well; Sleep Mode offloads/frees each partition the same way. The endpoints and workflow don’t change.A minimal script that launches two vLLM servers (Sleep Mode enabled), then runs one full cycle on each model:
A minimal script that launches two vLLM servers (Sleep Mode enabled), then runs one full cycle on each model:
- wake → warm‑up (1 token) → prompt → sleep
Notes
- Endpoints for sleeping/waking are outside
/v1: usePOST /sleep?sleep_level=...andPOST /wake_up. - This example uses Sleep Level 1. Change to
sleep_level=2when you won’t switch back soon or want to reclaim CPU RAM. - Logging prints timings for wake / warm‑up / prompt / sleep so you can see the first‑prompt drop.
# two_model_sleep_quickstart.py
# Minimal quickstart for Sleep Mode + Warm‑up in vLLM (two models)
import os, time, signal, subprocess, requests
from contextlib import contextmanager
from openai import OpenAI
A_MODEL = "Qwen/Qwen3-0.6B"
B_MODEL = "HuggingFaceTB/SmolVLM2-2.2B-Instruct"
A_PORT, B_PORT = 8001, 8002
A_URL, B_URL = f"http://localhost:{A_PORT}", f"http://localhost:{B_PORT}"
COMMON = [
"--enable-sleep-mode",
"--no-enable-prefix-caching",
"--dtype", "auto",
"--compilation-config", '{"full_cuda_graph": true}',
]
def run_vllm(model, port, extra_flags=None):
flags = extra_flags or []
cmd = [
"python3", "-m", "vllm.entrypoints.openai.api_server",
"--model", model, "--port", str(port),
*COMMON, *flags,
]
return subprocess.Popen(cmd, env=os.environ.copy())
def wait_ready(url, timeout=120):
t0 = time.time()
while time.time() - t0 < timeout:
try:
if requests.get(url + "/health", timeout=2).status_code == 200:
return True
except requests.RequestException:
pass
time.sleep(1)
raise RuntimeError(f"Server at {url} not ready in {timeout}s")
def client(base_url):
# vLLM OpenAI-compatible endpoint is served under /v1
return OpenAI(api_key="EMPTY", base_url=base_url + "/v1")
def post(url, path):
r = requests.post(url + path, timeout=10)
r.raise_for_status()
@contextmanager
def timed(label):
t0 = time.time()
yield
dt = time.time() - t0
print(f"{label:<18} {dt:.2f}s")
def warmup_call(url, model):
# 1-token warm‑up to absorb cold-start
client(url).chat.completions.create(
model=model,
messages=[{"role": "user", "content": "warm-up"}],
max_tokens=1,
temperature=0.0,
top_p=1.0,
extra_body={"seed": 0},
)
def user_prompt(url, model, text, max_tokens=32):
resp = client(url).chat.completions.create(
model=model,
messages=[{"role": "user", "content": text}],
max_tokens=max_tokens,
temperature=0.0,
top_p=1.0,
extra_body={"seed": 0},
)
return resp.choices[0].message.content
def cycle(url, model, text, sleep_level=1):
with timed("wake"):
post(url, "/wake_up")
with timed("warm-up"):
warmup_call(url, model)
with timed("prompt"):
out = user_prompt(url, model, text)
print("→", out.strip())
with timed(f"sleep(L{sleep_level})"):
post(url, f"/sleep?sleep_level={sleep_level}")
if __name__ == "__main__":
# SmolVLM2 needs trust-remote-code
a = run_vllm(A_MODEL, A_PORT)
b = run_vllm(B_MODEL, B_PORT, extra_flags=["--trust-remote-code"])
try:
wait_ready(A_URL); wait_ready(B_URL)
print("\n[A cycle]")
cycle(A_URL, A_MODEL, "Give me a fun fact about the Moon.", sleep_level=1)
print("\n[B cycle]")
cycle(B_URL, B_MODEL, "Describe an image pipeline in one line.", sleep_level=1)
finally:
a.terminate(); b.terminate()
try:
a.wait(timeout=5)
except Exception:
a.kill()
try:
b.wait(timeout=5)
except Exception:
b.kill()
Run
python two_model_sleep_quickstart.py
You’ll see logs like:
[A cycle]
wake 0.12s
warm-up 0.96s
prompt 2.55s
→ The Moon’s day is about 29.5 Earth days.
sleep(L1) 0.33s
...
Limits & when not to use it
- CPU RAM bound. Level‑1 offloads weights to CPU. Reserve roughly
param_count × bytes_per_param(bf16≈2 bytes, fp16≈2 bytes) plus overhead.- Example: 2.2B params × 2 bytes ≈ 4.4 GB baseline, expect ~5–6 GB with overheads.
- Level‑2 reload penalty. L2 frees CPU+GPU memory; the next wake reloads from disk and pays the full cold‑start again. Use L2 only when you won’t switch back soon.
- CUDA‑only. Sleep Mode isn’t available on ROCm or CPU‑only backends (as of v0.10.0).
- Heavy concurrency. Warm‑up is cheap but still a request—run it once per wake, not per thread. Many concurrent first‑requests can stampede into cold‑start work; serialize the warm‑up or gate the first request.